Monitoring Data Via Multiple Sources or a Central Solution?
For many or even most larger-scale operations, permits require many different media to be monitored (e.g. air, soil, surface or groundwater, and noise). Often this needs to be combined with supplementary data (e.g. production or weather) and meta-information (e.g. flows, height, location).
Different frequencies apply to different data streams, different compliance levels, calculations, and so on.
Often monitoring equipment comes with its own software but this rarely seeks to combine its data with data from all of the other equipment on the plant, field readings, and lab reports, etc. – nor manage many of the other permit requirement such as managing monitoring schedules, analysis of collated data sets or reporting. These information silos of data are often different from one another with varying interfaces and capabilities.
Data integration involves combining data residing in different sources and providing users with a unified view. An integrated system solves many of the problems inherent with information silos. They can;
- Hold and manage all key parts of the permit pertaining to monitoring.
- Manage the whole monitoring plan.
- Harvest, validate, and alert issues.
- Combine, Collate, aggregate, and calculate different data sets.
- Provide a single, uniform platform for analysing and reporting all monitoring data.
- Permit sharing of information across an organisation in a controlled, secure way.
- Prevent many instances of human error through copying and pasting from one system to another and into, for example, spreadsheets.
How should environmental monitoring data be organised?
With so many different datasets – how is it possible to combine them into one single interface? This needs a lot of skill and experience to do, however, with the right tools, it can be done with virtually any type of monitoring data.
Automation is also vital. Ideally, a system should minimise as much as possible the need for users to continually populate it with data and fix import problems.
Data collection
How is your data collected and housed today? In most cases, any organisation will have numerous different loggers or sensors, laboratory results, and production data. How is all this data managed today, most likely in spreadsheets or proprietary databases. In order to manage environmental data properly, there is a need to collate all these different sources into one, manageable location.
Layout
Files coming from multiple different silos will inevitably have almost as many different layouts as there are data sources, and it is usually simply not practical or possible to seek any consistency between them. Things like header information, column names, column order, file orientation – is every column a different parameter in a cross-tabulated layout, or maybe sample point headers, of the file could be a long list. So your importer needs to be intelligent and flexible. It must be able to read most files with no user input, to interpret column order and orientation, and so forth. Sometimes this will not be sufficient, so user configuration for special cases should be provided, along with the ability to insert custom scripts or macros to deal with the trickiest of layouts.
Special cases
Many data streams have special cases or rules which need applying. Some equipment might provide US dates. It is imperative that the importer knows this and how to handle it. Is 07/08/2018 August or July?
There are many varying date formats – 01/02/2018 2018-01-02 01-Feb-2018 and so on.
Many .csv files have comma column separators, but other delineators can be found such as semi-colon or tab. The importer needs to know which to expect.
Other files may be missing columns. For example, a flow meter knows which meter it is and might not include its name in the output file. This would have to be specified to the importer, or ‘all files arriving in the is folder is from x laboratory’, etc.
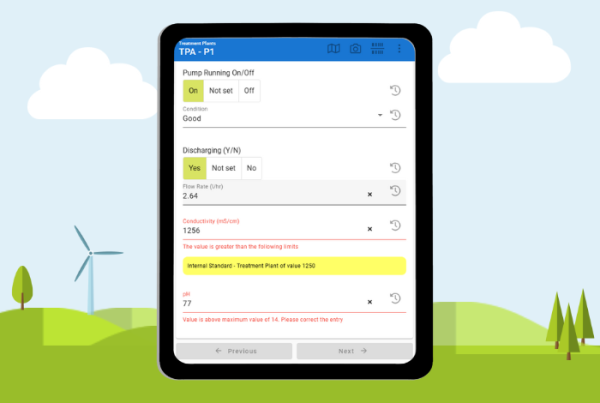
With laboratory readings, < symbols are common (e.g. <0.01). They simply mean ‘below detection limit’. This doesn’t mean zero, but different regulators have different requirements for their handling. Is it the full amount up to the detection limit, half of it or zero? Your importer needs to know which in order that it can interpret not just as text, and post the correct number in the database for use in interpretation, but also as a text for reports.
Comma decimal separators (e.g. 0,01) are common especially in continental Europe or Latin American countries. The importer needs to understand that this is not a column separator but a decimal ‘point’.
So on setup, the user or administrator must have choices and flexibility on how to set up any data stream.
Consistency
Naming can be a huge problem if not handled correctly. Different equipment might call the same location something different, e.g. ‘channel 1’ might identify the same location as ‘stack 1’, or overtime people manually recording a name differently, e.g. BH1 BH01, Borehole 1. These must all be combined, and the imported has to know the variants. A good importer will learn these aliases over time and hold the mappings in order that it only needs to ask once.
Format
Can your system handle multiple file formats, for example, CSV files, Excel spreadsheets, text files?
Calculations
Automatic aggregation and calculation are often not as simple as it might seem. Take one seemingly simple example of a mg/m3 compliance limit. There might be a sensor measuring mg/l and a flow meter measuring m3/minute, both at different intervals. The calculator must know where to search back in time to find the nearest applicable reading to use. Or rules on how to handle a meter going round and back to zero. Once the result is obtained, there may now be a new data set that now needs a compliance check (and alert if appropriate). There are many complications that need handling.
To conclude, there are many reasons for integrating environmental systems and have listed the most common difficulties. Let the experts help you achieve a smooth and streamlined implementation and drive your business forward with easy to use environmental intelligence.
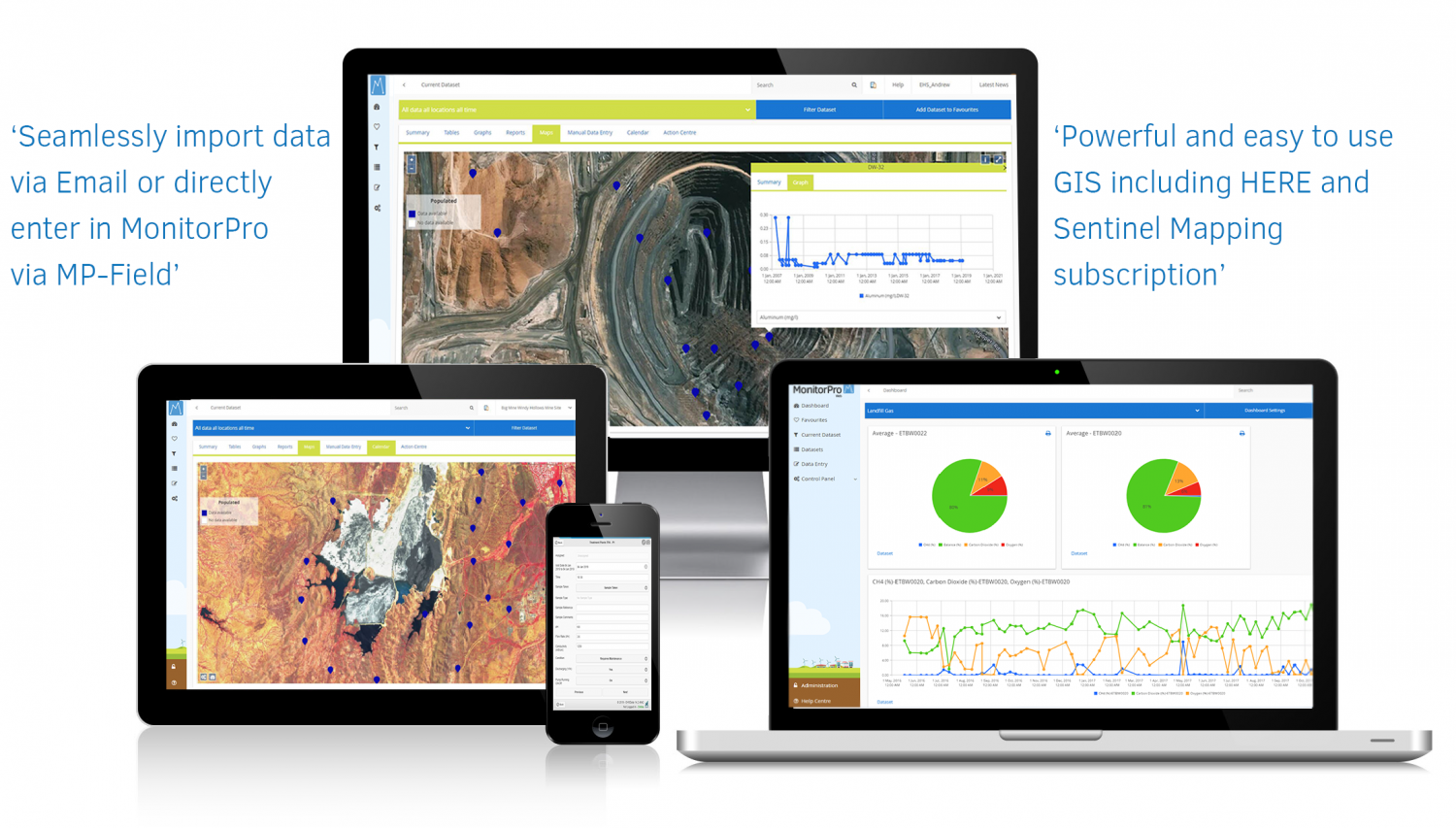
About MonitorPro
The complete, professional environmental data monitoring solution, MonitorPro is the IT solution trusted by environmental teams worldwide to manage their environmental compliance and data collection. MonitorPro is a web-based or locally hosted solution for the collation of ALL sources of environmental data, where it is generated by loggers, laboratories, weather stations, calculations, or other data repositories. MonitorPro is the first EHS Software solution to receive an MCERTS accreditation from the Environmental Agency.
About EHS Data
EHS Data is a world leading UK based software company providing Environmental Data Management Solutions to over 1,000 sites in 40 countries worldwide. For over 20 years, our versatile software solution, MonitorPro, has helped organisations save time, improve planning, quality control, site analysis and reporting to manage environmental obligations and sustainability.
ISO 27001
EHS Data is ISO 27001 certified.
A Carbon Negative Business
In 2020, EHS Data attained Carbon negative status and is committed to maintaining this status each year.